
Recent Posts
Archives
Categories
Join 15 other subscribers
| M | T | W | T | F | S | S |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||
A. Makelov
Hi all, here’s a brief summary of my 13th (and last) week of GSoC.
_size attribute to the Permutation class, and then, when faced with something like Permutation([[2, 3], [4, 5, 6], [8]]), find the maximum index appearing in the permutation (here it’s 8) and assign the size of the permutation to that + 1. Then it remains to adjust some of the other methods in the class (after I adjusted mul so that it treats permutations of different sizes as if they leave all points outside their domain fixed, all the tests passed) so that they make sense with that new approach to cyclic forms.ExtendedArrayForm or something, with a field _array_form that holds the usual array form of a permutation. Then we overload the __getitem__ method so that if the index is outside the bounds of self._array_form we return the index unchanged. Of course, we’ll have to overload other things, like the __len__ and __str__ to make it behave like a list. Then instead of using a list to initialize the array form of a permutation, we use the corresponding ExtendedArrayForm. This will make all permutations behave as if they are acting on a practically infinite domain, and if we do it that way, we won’t have to make any changes to the methods in Permutation – everything is going to work as expected, no casework like if len(a) > len(b),... will be needed. So this sounds like a rather elegant approach. On the other hand, I’m not entirely sure if it is possible to make it completely like a list, and also it doesn’t seem like a very performance-efficient decision since ExtendedArrayForm instances will be created all the time. (see the discussion here).That’s it for now, and that’s the end of my series of blog posts for the GSoC, but I don’t really feel that something has ended since it seems that my contributions to the combinatorics module will continue (albeit not that regularly : ) ). After all, it’s a lot of fun, and there are a lot more things to be implemented/fixed there! So, a big “Thank you” to everyone who helped me get through (and to) GSoC, it’s been a pleasure and I learned a lot. Goodbye!
Hi all, here’s a brief summary of the 12th week of my GSoC:
# line 29: set the next element from the current branch and update # accorndingly c[l] += 1 element = ~(computed_words[l - 1])
should be replaced with
# line 29: set the next element from the current branch and update
# accorndingly
c[l] += 1
if l == 0:
element = identity
else:
element = ~(computed_words[l - 1])
since we might be at the bottom level with 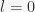
def center(self):
return self.centralizer(self)
was used. This can be updated later when I (or someone else) figures out the polynomial-time algorithm.
In [68]: from sympy.combinatorics.named_groups import * In [69]: S = SymmetricGroup(4) In [70]: ds = S.derived_series() In [71]: len(ds) Out[71]: 4 In [72]: ds[1] == AlternatingGroup(4) Out[72]: True In [73]: ds[2] == DihedralGroup(2) Out[73]: True In [74]: ds[3] == PermutationGroup([Permutation([0, 1, 2, 3])]) Out[74]: True
demonstrating the well-known normal series of groups 
I wrote docstrings for the new stuff, and my current work can be found on my week10 branch. There will be some comprehensive test following the new additions (and I’ll need GAP to verify the results of some of them, probably). It seems that Todd-Coxeter won’t happen during GSoC since there’s just one more week; instead, I plan to focus on improving disjoint cycle notation and group databases.
[1] Derek F. Holt, Bettina Eick, Bettina, Eamonn A. O’Brien, “Handbook of computational group theory”, Discrete Mathematics and its Applications (Boca Raton). Chapman & Hall/CRC, Boca Raton, FL, 2005. ISBN 1-58488-372-3
Hi all, here’s a brief summary of the 11th week of my GSoC.
In [4]: from sympy.combinatorics.named_groups import * In [5]: A = AlternatingGroup(9) In [6]: G = A.pointwise_stabilizer([2, 3, 5]) In [7]: G == A.stabilizer(2).stabilizer(3).stabilizer(5) Out[7]: True
(this is much faster than the naive implementation using .stabilizer() repeatedly), and the centralizer of a group 
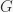
In [11]: from sympy.combinatorics.named_groups import * In [12]: S = SymmetricGroup(6) In [13]: A = AlternatingGroup(6) In [14]: C = CyclicGroup(6) In [15]: S_els = list(S.generate()) In [16]: G = S.centralizer(A) In [17]: G.order() Out[17]: 1 In [18]: temp = [[el*gen for gen in A.generators] == [gen*el for gen in A.generators] for el in S_els] In [19]: temp.count(False) Out[19]: 719 In [20]: temp.count(True) Out[20]: 1 In [21]: G = S.centralizer(C) In [22]: G == C Out[22]: True In [23]: temp = [[el*gen for gen in C.generators] == [gen*el for gen in C.generators] for el in S_els] In [24]: temp.count(True) Out[24]: 6
(it takes some effort to see that these calculations indeed prove that .centralizer() returned the needed centralizer). The centralizer algorithm uses a pruning criterion described in [1], and even though it’s exponential in complexity, it’s fast for practical purposes. Both of the above functions are available (albeit not documented yet) on my week10 branch.
That’s it for now!
[1] Derek F. Holt, Bettina Eick, Bettina, Eamonn A. O’Brien, “Handbook of computational group theory”, Discrete Mathematics and its Applications (Boca Raton). Chapman & Hall/CRC, Boca Raton, FL, 2005. ISBN 1-58488-372-3
Hi all,
here’s a brief summary of what I’ve been doing during the 10th week of my GSoC.
In [87]: S = SymmetricGroup(5) In [88]: prop_fix_3 = lambda x: x(3) == 3 In [89]: %autoreload In [90]: S.subgroup_search(prop_fix_3) --------------------------------------------------------------------------- StopIteration Traceback (most recent call last) <ipython-input-90-6b85aa1285b8> in <module>() ----> 1 S.subgroup_search(prop_fix_3) /home/alexander/workspace/sympy/sympy/combinatorics/perm_groups.py in subgroup_search(self, prop, base, strong_gens, tests, init_subgroup) 2660 2661 # this function maintains a partial BSGS structure up to position l -> 2662 _insert_point_in_base(res, res_base, res_strong_gens, l, new_point, distr_gens=res_distr_gens, basic_orbits=res_basic_orbits, transversals=res_transversals) 2663 # find the l+1-th basic stabilizer 2664 new_stab = PermutationGroup(res_distr_gens[l + 1]) /home/alexander/workspace/sympy/sympy/combinatorics/util.py in _insert_point_in_base(group, base, strong_gens, pos, point, distr_gens, basic_orbits, transversals) 423 # baseswap with the partial BSGS structures. Notice that we need only 424 # the orbit and transversal of the new point under the last stabilizer --> 425 new_base, new_strong_gens = group.baseswap(partial_base, strong_gens, pos, randomized=False, transversals=partial_transversals, basic_orbits=partial_basic_orbits, distr_gens=partial_distr_gens) 426 # amend the basic orbits and transversals 427 stab_pos = PermutationGroup(distr_gens[pos]) /home/alexander/workspace/sympy/sympy/combinatorics/perm_groups.py in baseswap(self, base, strong_gens, pos, randomized, transversals, basic_orbits, distr_gens) 2472 # ruling out member of the basic orbit of base[pos] along the way 2473 while len(current_group.orbit(base[pos])) != size: -> 2474 gamma = iter(Gamma).next() 2475 x = transversals[pos][gamma] 2476 x_inverse = ~x StopIteration:
The reason is certainly the change of base performed on line 11 in the pseudocode (this is also indicated in my code on my local week6 branch here ). The use of the function BASESWAP there is what gets us into trouble. It is meant to be applied to base and a strong generating set relative to it, switch two consecutive base points and change the generating set accordinly. However, in subgroup_search the goal is to change a base 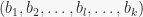




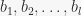

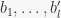
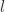
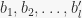
 and change it accordingly as the base is changed, using the function stabilizer() in sympy/combinatorics/perm_groups.py. For each base change we have to calculate one more stabilizer, so that’s not terrible. It is also sort of suggested in “Notes on Computational Group Theory” by Alexander Hulpke (page 34). The problem with this approach is that stabilizer() tends to return a group with many generators, and repeated applications keep increasing this number. However, using this removed the bug from SUBGROUPSEARCH. As before, more comprehensive tests are on the way : )
and change it accordingly as the base is changed, using the function stabilizer() in sympy/combinatorics/perm_groups.py. For each base change we have to calculate one more stabilizer, so that’s not terrible. It is also sort of suggested in “Notes on Computational Group Theory” by Alexander Hulpke (page 34). The problem with this approach is that stabilizer() tends to return a group with many generators, and repeated applications keep increasing this number. However, using this removed the bug from SUBGROUPSEARCH. As before, more comprehensive tests are on the way : )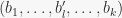 and the strong generating set for
and the strong generating set for  . There will likely be redundant generators after that, and it will probably involve more computation than finding a single stabilizer. However, in the long run (since there are many base changes performed) this might perform faster (due to the increasing number of generators that stabilizer() tends to create). I have not tried that approach yet.
. There will likely be redundant generators after that, and it will probably involve more computation than finding a single stabilizer. However, in the long run (since there are many base changes performed) this might perform faster (due to the increasing number of generators that stabilizer() tends to create). I have not tried that approach yet.That’s it for now : )
Hi all, here’s a brief summary of what I’ve been doing for the 9th week of my GSoC.
This week saw (and still has to see) some exciting new additions:
I. The incremental Schreier-Sims algorithm.
This is a version of the Schreier-Sims algorithm that takes a sequence of points 
![[]](https://s0.wp.com/latex.php?latex=%5B%5D&bg=f7f7f7&fg=242424&s=0&c=20201002)

In [41]: S = SymmetricGroup(5) In [42]: base = [3, 4] In [43]: gens = S.generators In [44]: x = S.schreier_sims_incremental(base, gens) In [45]: x Out[45]: ([3, 4, 0, 1], [Permutation([1, 2, 3, 4, 0]), Permutation([1, 0, 2, 3, 4]), Permutation([4, 0, 1, 3, 2]), Permutation([0, 2, 1, 3, 4])]) In [46]: from sympy.combinatorics.util import _verify_bsgs In [47]: _verify_bsgs(S, x[0], x[1]) Out[47]: True
The current implementation stores the transversals for the basic orbits explicitly (the alternative is to use Schreier vectors to describe the orbits – this saves a lot of space, but requires more time in order to compute transversal elements whenever they are needed. This feature is still to be implemented, and this probably won’t happen in this GSoC). The current implementation of the Schreier-Sims algorithm on the master branch uses Jerrum’s filter (for more details and comparisons of the incremental version and the one using Jerrum’s filter, go here) as an optimization, and also stores the transversals explicitly. The incremental version seems to be asymptotically faster though. Here’s several comparisons of the current version on the master branch and the incremental one which can be found on a local branch of mine which is somewhat inadequately called week6):
For symmetric groups:
In [50]: groups = [] In [51]: for i in range(20, 30): ....: groups.append(SymmetricGroup(i)) ....: In [52]: for group in groups: ....: %timeit -r1 -n1 group.schreier_sims() ....: 1 loops, best of 1: 590 ms per loop 1 loops, best of 1: 719 ms per loop 1 loops, best of 1: 981 ms per loop 1 loops, best of 1: 1.35 s per loop 1 loops, best of 1: 1.66 s per loop 1 loops, best of 1: 2.19 s per loop 1 loops, best of 1: 2.74 s per loop 1 loops, best of 1: 3.37 s per loop 1 loops, best of 1: 4.28 s per loop 1 loops, best of 1: 5.37 s per loop In [53]: for group in groups: ....: %timeit -r1 -n1 group.schreier_sims_incremental() ....: 1 loops, best of 1: 612 ms per loop 1 loops, best of 1: 737 ms per loop 1 loops, best of 1: 927 ms per loop 1 loops, best of 1: 1.15 s per loop 1 loops, best of 1: 1.41 s per loop 1 loops, best of 1: 1.72 s per loop 1 loops, best of 1: 2.1 s per loop 1 loops, best of 1: 2.52 s per loop 1 loops, best of 1: 3.02 s per loop 1 loops, best of 1: 3.58 s per loop
For alternating groups:
In [54]: groups = [] In [55]: for i in range(20, 40, 2): ....: groups.append(AlternatingGroup(i)) ....: In [56]: for group in groups: %timeit -r1 -n1 group.schreier_sims() ....: 1 loops, best of 1: 613 ms per loop 1 loops, best of 1: 1.03 s per loop 1 loops, best of 1: 1.77 s per loop 1 loops, best of 1: 2.65 s per loop 1 loops, best of 1: 3.51 s per loop 1 loops, best of 1: 5.31 s per loop 1 loops, best of 1: 7.71 s per loop 1 loops, best of 1: 11.1 s per loop 1 loops, best of 1: 15.3 s per loop 1 loops, best of 1: 19.1 s per loop In [57]: for group in groups: %timeit -r1 -n1 group.schreier_sims_incremental() ....: 1 loops, best of 1: 504 ms per loop 1 loops, best of 1: 787 ms per loop 1 loops, best of 1: 1.23 s per loop 1 loops, best of 1: 1.9 s per loop 1 loops, best of 1: 2.8 s per loop 1 loops, best of 1: 3.99 s per loop 1 loops, best of 1: 5.48 s per loop 1 loops, best of 1: 7.45 s per loop 1 loops, best of 1: 10 s per loop 1 loops, best of 1: 13.2 s per loop
And for some dihedral groups of large degree (to illustrate the case of small-base groups of large degrees):
In [58]: groups = [] In [59]: for i in range(100, 2000, 200): ....: groups.append(DihedralGroup(i)) ....: In [60]: for group in groups: %timeit -r1 -n1 group.schreier_sims() ....: 1 loops, best of 1: 29.6 ms per loop 1 loops, best of 1: 108 ms per loop 1 loops, best of 1: 278 ms per loop 1 loops, best of 1: 527 ms per loop 1 loops, best of 1: 861 ms per loop 1 loops, best of 1: 1.29 s per loop 1 loops, best of 1: 1.83 s per loop 1 loops, best of 1: 2.39 s per loop 1 loops, best of 1: 3.06 s per loop 1 loops, best of 1: 3.83 s per loop In [61]: for group in groups: %timeit -r1 -n1 group.schreier_sims_incremental() ....: 1 loops, best of 1: 20.8 ms per loop 1 loops, best of 1: 52.8 ms per loop 1 loops, best of 1: 121 ms per loop 1 loops, best of 1: 223 ms per loop 1 loops, best of 1: 365 ms per loop 1 loops, best of 1: 548 ms per loop 1 loops, best of 1: 766 ms per loop 1 loops, best of 1: 1 s per loop 1 loops, best of 1: 1.25 s per loop 1 loops, best of 1: 1.51 s per loop
In addition to this algorithm I implemented a related function _remove_gens in sympy.combinatorics.util which removes redundant generators from a strong generating set (since there tend to be some redundant ones after schreier_sims_incremental() is run):
In [68]: from sympy.combinatorics.util import _remove_gens In [69]: S = SymmetricGroup(6) In [70]: base, strong_gens = S.schreier_sims_incremental() In [71]: strong_gens Out[71]: [Permutation([1, 2, 3, 4, 5, 0]), Permutation([1, 0, 2, 3, 4, 5]), Permutation([0, 5, 1, 2, 3, 4]), Permutation([0, 1, 2, 3, 5, 4]), Permutation([0, 1, 2, 4, 3, 5]), Permutation([0, 1, 3, 2, 4, 5]), Permutation([0, 1, 2, 5, 4, 3]), Permutation([0, 1, 5, 3, 4, 2])] In [72]: new_gens = _remove_gens(base, strong_gens) In [73]: new_gens Out[73]: [Permutation([1, 0, 2, 3, 4, 5]), Permutation([0, 5, 1, 2, 3, 4]), Permutation([0, 1, 2, 4, 3, 5]), Permutation([0, 1, 2, 5, 4, 3]), Permutation([0, 1, 5, 3, 4, 2])] In [74]: _verify_bsgs(S, base, new_gens) Out[74]: True
II. Subgroup search.
This is an algorithm used to find the subgroup 

In [77]: S = SymmetricGroup(6) In [78]: prop = lambda g: g.is_even In [79]: G = S.subgroup_search(prop) In [80]: G == AlternatingGroup(6) Out[80]: True
to find the alternating group as a subgroup of the full symmetric group by the defining property that all its elements are the even permutations, or this:
In [81]: D = DihedralGroup(10) In [82]: prop_true = lambda g: True In [83]: G = D.subgroup_search(prop_true) In [84]: G == D Out[84]: True
to find the dihedral group 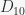
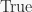
In [106]: A = AlternatingGroup(4) In [107]: G = A.subgroup_search(prop_fix_23) In [108]: G == A.stabilizer(2).stabilizer(3) Out[108]: True
to find the pointwise stabilizer of 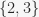
In [119]: A = AlternatingGroup(5) In [120]: base, strong_gens = A.schreier_sims_incremental() In [121]: G = A.subgroup_search(prop_fix_1, base=base, strong_gens=strong_gens) In [122]: G == A.stabilizer(1) Out[122]: True In [123]: _verify_bsgs(G, base, G.generators) Out[123]: True
The bad news is that the function breaks somewhere. For example:
In [125]: S = SymmetricGroup(7) In [126]: prop_true = lambda g: True In [127]: G = S.subgroup_search(prop_true) In [128]: G == S Out[128]: False
This needs some really careful debugging, but overall it looks promising since it works in so many cases – so the bug is hopefully small : ).
So, that’s it for now!
[1] Derek F. Holt, Bettina Eick, Bettina, Eamonn A. O’Brien, “Handbook of computational group theory”, Discrete Mathematics and its Applications (Boca Raton). Chapman & Hall/CRC, Boca Raton, FL, 2005. ISBN 1-58488-372-3
Hi everyone, here’s a brief summary of what I’ve been doing for the 8th week of my GSoC:
with a BSGS, a subgroup  with a BSGS having the same base as that of , a property such that
with a BSGS having the same base as that of , a property such that  for
for  is either true or false, is always true for $g \in K$, and the elements of satisfying form a subgroup , and tests
is either true or false, is always true for $g \in K$, and the elements of satisfying form a subgroup , and tests 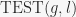 used to rule out group elements (i.e., make sure they don’t satisfy ) based on the image of the first base points of , the so-called partial base image. It modifies by adding generators until
used to rule out group elements (i.e., make sure they don’t satisfy ) based on the image of the first base points of , the so-called partial base image. It modifies by adding generators until 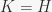 , and returns a strong generating set for . It performs a depth-first search over all possible base images (which by the definition of a base determine uniquely every element of ), but uses several conditions to prune the search tree and is said to be fast in practice. This algorithm is the basis for finding normalizers and centralizers and intersections of subgroups, so it’s pretty fundamental. One of its features is the frequent change of base for : at level in the search tree we want to make sure that the base for starts with the current partial base image (i.e., the image of the first points in the base). In [1] it is said that this requires only one application of BASESWAP (which swaps two neighbouring base points). This was confusing me for a while. However, since we want to only change the -th base point at any base change, and the base after the -th point doesn’t matter at level , it seems that we can do the following. Treat the partial base image, denote it by
, and returns a strong generating set for . It performs a depth-first search over all possible base images (which by the definition of a base determine uniquely every element of ), but uses several conditions to prune the search tree and is said to be fast in practice. This algorithm is the basis for finding normalizers and centralizers and intersections of subgroups, so it’s pretty fundamental. One of its features is the frequent change of base for : at level in the search tree we want to make sure that the base for starts with the current partial base image (i.e., the image of the first points in the base). In [1] it is said that this requires only one application of BASESWAP (which swaps two neighbouring base points). This was confusing me for a while. However, since we want to only change the -th base point at any base change, and the base after the -th point doesn’t matter at level , it seems that we can do the following. Treat the partial base image, denote it by 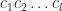 , as a base, and then run BASESWAP on
, as a base, and then run BASESWAP on 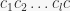 , interchanging the last two elements, where
, interchanging the last two elements, where  is the new -th point in the base. Now I’m more confident that I can implement SUBGROUP search (the other parts of the procedure are easily approachable). But there is one other problem with it:, the group we initialize with, to have the same base as . The current deterministic implementation of the Schreier-Sims algorithm (using Jerrum’s filther) always produces a BSGS from scratch, and therefore we can’t tell it to make a BSGS for with respect to some particular base. Hence we need an implementation of the so-called “incremental” Schreier-Sims algorithm, which takes a sequence of points and a generating set and extends them to a BSGS. This is also described in [1], together with some optimizations, and it won’t be very hard to go through the pseudocode and implement it – so that’ going to be the next step. It would also be a useful addition to the entire group-theoretical module since often in algorithms we want a BSGS with respect to some convenient base.
is the new -th point in the base. Now I’m more confident that I can implement SUBGROUP search (the other parts of the procedure are easily approachable). But there is one other problem with it:, the group we initialize with, to have the same base as . The current deterministic implementation of the Schreier-Sims algorithm (using Jerrum’s filther) always produces a BSGS from scratch, and therefore we can’t tell it to make a BSGS for with respect to some particular base. Hence we need an implementation of the so-called “incremental” Schreier-Sims algorithm, which takes a sequence of points and a generating set and extends them to a BSGS. This is also described in [1], together with some optimizations, and it won’t be very hard to go through the pseudocode and implement it – so that’ going to be the next step. It would also be a useful addition to the entire group-theoretical module since often in algorithms we want a BSGS with respect to some convenient base.More or less, that’s it for now. In the next few days I’ll try to write some actual code implementing the above two bullets and get some more reviewing for my most recent pull request.
[1] Derek F. Holt, Bettina Eick, Bettina, Eamonn A. O’Brien, “Handbook of computational group theory”, Discrete Mathematics and its Applications (Boca Raton). Chapman & Hall/CRC, Boca Raton, FL, 2005. ISBN 1-58488-372-3
Hi all,
here’s a brief summary of what I’ve been doing during the 7th week of my GSoC, as well as a general overview of what’s going on and where things are going with computational group theory in sympy.
Things I did during the week.
This week I focused on:
So here are the naming conventions for working with a BSGS:
degree – the degree of the permutation group.
base – This is sort of obvious. A base for a permutation group 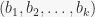
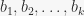
base_len – the number of elements in a base.
strong_gens – the strong generating set (relative to some base). This is implemented as a list of Perm objects.
basic_stabilizers – For a base 

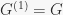
distr_gens – the strong generators distributed according to the basic stabilizers. This means: for a base 

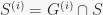


basic_orbits – these are the orbits of 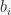
basic_transversals – these are transversals for the basic orbits. Notice that the choice for these may not (and in most cases won’t be) unique. For one thing, it depends on the set of strong generators present (which is also not uniquely determined for a given base). They are implemented as a list of dictionaries indexed according to the base
I wrote functions extracting basic_orbits, basic_transversals, basic_stabilizers, distr_gens from only a base and strong generating set, as well as functions for extracting all of them from a base, strong generating set, and a part of them, so that if any of them is available, it can be supplied in order to avoid recalculations.
Also, there is a straightforward test _verify_bsgs in sympy.combinatorics.util that tests a sequence of points and group elements for being a base and strong generating set. It simply verifies the definition of a base and strong generating set relative to it. There will likely be other ways to do that in the future – more effective, but surely more complicated and thus error-prone. This will serve as a robust testing tool
Where we are.
So, here’s a checklist of what I’ve promised in my proposal on the melange website, and which parts of it have already been implemented. This is reading the optimistic timeline. This all pertains to permutation groups, unless specified:
Things yet to be done.
Apart from the things that got a “NO” on the list above, the following currently come to mind (I’ll update this list periodically):
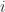 -th and
-th and  -th transversals are calculated.
-th transversals are calculated.Well, that’s it for now it seems. If anything else pops up soon, I’ll add it here!
Hi all,
here’s a brief summary of what I’ve been doing for the sixth week of my GSoC:
 instead of
instead of 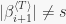 . At first I implemented the algorithm the way it was given is pseudocode, and lost many hours (it wasn’t working) until I discovered that this little detail might be wrong. Now, I shall assume the notation used in [1] in order to follow their argument as closely as possible. My reasoning is as follows: as we change the set
. At first I implemented the algorithm the way it was given is pseudocode, and lost many hours (it wasn’t working) until I discovered that this little detail might be wrong. Now, I shall assume the notation used in [1] in order to follow their argument as closely as possible. My reasoning is as follows: as we change the set  during the run of BASESWAP, we finally want to have
during the run of BASESWAP, we finally want to have 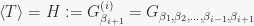 . The last line
. The last line  on page 102 of [1] is indeed correct by a straightforward application of the orbit-stabilizer theorem; so if we put
on page 102 of [1] is indeed correct by a straightforward application of the orbit-stabilizer theorem; so if we put  we indeed have
we indeed have  . Up to this point, I believe the book. However, after that they say that the last equation implies that
. Up to this point, I believe the book. However, after that they say that the last equation implies that 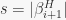 . Looking more closely, by definitions we recall that
. Looking more closely, by definitions we recall that  . Hence,
. Hence, 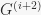 is the stabilizer of
is the stabilizer of 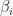 in , thus by the orbit-stabilizer theorem we have
in , thus by the orbit-stabilizer theorem we have  , hence we must have
, hence we must have 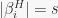 , not
, not 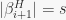 . This same mistake (
. This same mistake (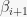 instead of ) appears several other times (in fact, all the times) in the discussion of BASESWAP and once in the pseudocode. Now that I changed it to , the implementation doesn’t break and behaves as expected. I also implemented the randomized version described in [1], p.103 and [2], p.98, and it also behaves as expected. I’d be extremely happy if anyone else is willing to go over this and check whether what I’m saying is true; I’m pretty sure it is, but I didn’t expect to find such a serious mistake in that book. I’m willing to provide their argument in its entirety or clarify the notation, just shoot me a comment below.
instead of ) appears several other times (in fact, all the times) in the discussion of BASESWAP and once in the pseudocode. Now that I changed it to , the implementation doesn’t break and behaves as expected. I also implemented the randomized version described in [1], p.103 and [2], p.98, and it also behaves as expected. I’d be extremely happy if anyone else is willing to go over this and check whether what I’m saying is true; I’m pretty sure it is, but I didn’t expect to find such a serious mistake in that book. I’m willing to provide their argument in its entirety or clarify the notation, just shoot me a comment below.So, that’s it for now. I’m in the process of furnishing my code for the next pull request (which will hopefully be submitted tomorrow), and then I’ll resume my work on subgroup intersections.
Edit: My pull request has not been submitted yet since writing the docstrings and tests took me longer than expected. The current state of it is available here, if anyone wants to take a look at how things are going. I still have to write some more tests, and hopefully will push it today for review.
Edit#2: The pull request is finally out. It is some 1300 lines of code, so if people object I can remove some of the stuff and save them for a future pull request.
[1] Derek F. Holt, Bettina Eick, Bettina, Eamonn A. O’Brien, “Handbook of computational group theory”, Discrete Mathematics and its Applications (Boca Raton). Chapman & Hall/CRC, Boca Raton, FL, 2005. ISBN 1-58488-372-3
[2] Permutation Group Algorithms, Ákos Seress, Cambridge University Press
Hi everyone,
here’s a brief summary of what I’ve been doing for the fifth week of my GSoC.
In [297]: S = SymmetricGroup(4) In [298]: S.schreier_sims() In [299]: S._coset_repr Out[299]: [[[0, 1, 2, 3], [1, 2, 3, 0], [2, 3, 0, 1], [3, 0, 1, 2]], [[0, 1, 2, 3], [0, 2, 1, 3], [0, 3, 1, 2]], [[0, 1, 2, 3], [0, 1, 3, 2]]] In [300]: S._base Out[300]: [0, 1, 2]
From this and similar examples I concluded that the i-th component of _coset_repr is a transversal of the i-th basic orbit of the group S and tried to use this in PRINTELEMENTS. However, consired the following example:
In [302]: G = PermutationGroup([Permutation([[0, 1, 2, 3], [4], [5]]), Permutation([[1, 3], [0], [2], [4], [5]]), Permutation([[0], [1], [2], [3], [4, 5]])]) In [303]: G.schreier_sims() In [304]: G._base Out[304]: [0, 1, 4] In [305]: G._coset_repr Out[305]: [[[0, 1, 2, 3, 4, 5], [1, 2, 3, 0, 4, 5], [2, 3, 0, 1, 4, 5], [3, 0, 1, 2, 4, 5]], [[0, 1, 2, 3, 4, 5], [0, 3, 2, 1, 4, 5]], [[0, 1, 2, 3, 4, 5]], [[0, 1, 2, 3, 4, 5]], [[0, 1, 2, 3, 4, 5], [0, 1, 2, 3, 5, 4]]]
Here, the first two components of _coset_repr are as I expected, but the 3rd and 4th are something I didn’t expect to be there (I expected to get the 5th component instead of the 3rd, and no more components). Hence at present the behaviour of _coset_repr is not too clear to me. The current solution is to use the randomized version of the Schreier-Sims algorithm to get a base and a strong generating set. Another option would be to use the generators from the attribute _stabilizers_gens, but I haven’t tried that yet. Anyway, PRINTELEMENTS works now (edit: there are many other algorithms present for printing all the elements of a group, but this one is significant for the implementation of backtrack searches), and the order in which the elements of the group are visited (lexicographically with respect to the image of the base, in an ordering of 
That’s it for now. Next week, I’ll continue with backtrack searches, and hopefully will implement the subgroup intersection routine (it seems formidable right now)… and put some more effort into getting the second pull request merged – I’ve got a lot to catch up with in terms of getting my code in sympy : ) .
[1] Derek F. Holt, Bettina Eick, Bettina, Eamonn A. O’Brien, “Handbook of computational group theory”, Discrete Mathematics and its Applications (Boca Raton). Chapman & Hall/CRC, Boca Raton, FL, 2005. ISBN 1-58488-372-3
Hi everyone,
Here’s a brief summary of what I’ve been doing for the 4-th week of my GSoC.
This week, like the previous one, was not intense in terms of coding. Here’s what I have up and running, basically what I was talking about last week:
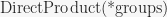 that constructs the direct product of several groups. For more than two groups,
that constructs the direct product of several groups. For more than two groups, 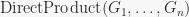 is several times faster than calling
is several times faster than calling 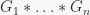 (benchmarked it), thus it makes sense to have such a function. This is later used in constructing an arbitrary abelian group by its cycle decomposition.
(benchmarked it), thus it makes sense to have such a function. This is later used in constructing an arbitrary abelian group by its cycle decomposition.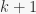 -tuple
-tuple  for
for 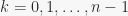 and check if it spans all possible -tuples. This is really bad since the number of tuples is growing like
and check if it spans all possible -tuples. This is really bad since the number of tuples is growing like  , hence the complexity is
, hence the complexity is  where
where  is the degree of transitivity,
is the degree of transitivity,  is the number of generators. It seems that some sort of randomization that checks only several randomly chosen tuples for membership in the orbit will decrease the complexity, but to make sure we still need to do all the checks if the random tuples pass, which is again . Some bound on the probability will be good to know here.
is the number of generators. It seems that some sort of randomization that checks only several randomly chosen tuples for membership in the orbit will decrease the complexity, but to make sure we still need to do all the checks if the random tuples pass, which is again . Some bound on the probability will be good to know here.The main focus this week was on several discussions about future changes in the permutation groups module, and on making some more effort to get my code so far merged 🙂 :
So, that’s it for now. Next week I’ll focus on getting some more of my code merged and backtrack searches.
[1] Holt, D., Eick, B., O’Brien, E. “Handbook of computational group theory”
